Hadoop中namenode和secondarynamenode工作机制讲解
脚本宝典收集整理的这篇文章主要介绍了Hadoop中namenode和secondarynamenode工作机制讲解,脚本宝典觉得挺不错的,现在分享给大家,也给大家做个参考。
1)流程
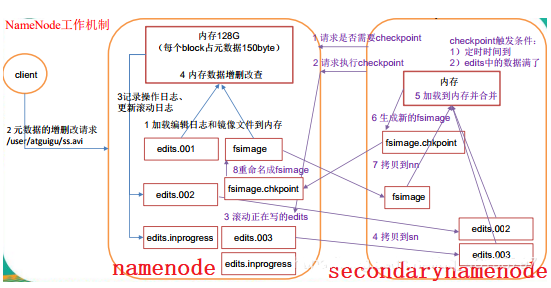
2)FSImage和Edits
nodenode是HDFS的大脑,它维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以俩种文件存储在文件系统:一种是命名空间镜像(也称为文件系统镜像,File System Image,FSImage),即HDFS元数据的完整快照,每次NameNode启动的时候,默认会加载最新的命名空间镜像,另一种是命令空间镜像的编辑日志(Edit log)。
FSImage文件其实是文件系统元数据的一个永久性检查点,但并非每一个写操作都会更新这个文件,因为FSImage是一个大型文件,如果频繁地执行写操作,会使系统运行极为缓慢。解决方案是NameNode只将改动内容预写日志,即写入命名空间镜像的编辑日志.随着时间的推移,编辑日志会变得越来越大,那么一旦发生故障,将会话费非常多的时间来回滚操作,所以就像传统的关系数据库一样,需要定期地合并FSImage和编辑日志。如果由NameNode来做合并操作,那么NameNode在为集群提供服务时可能无法提供足够的资源,为了彻底解决这一问题,SecondaryNameNode应允而生。
3)第一阶段:namenode 启动
- (1)第一次启动 namenode 格式化后,创建 fsimage 和 edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- (2)客户端对元数据进行增删改的请求。
- (3)namenode 记录操作日志,更新滚动日志。
- (4)namenode 在内存中对数据进行增删改查。
4)第二阶段:Secondary NameNode 工作
- (1)Secondary NameNode 询问 namenode 是否需要 checkpoint。直接带回 namenode 是否检查结果。
- (2)Secondary NameNode 请求执行 checkpoint。
- (3)Secondary NameNode引导namenode 滚动更新编辑正在写的 edits 日志。
- (4) Secondary NameNode载入FSImage文件,回放编辑日志,将其合并到FSImage,将新的FSImage文件压缩后写入磁盘。
- (5)拷贝 fsimage到 namenode。
- (6)namenode 将 fsimage重新命名成 fsimage。
默认情况下,该过程每小时发生一次,或者当NameNode的编辑日志文件到达默认的64MB也会触发。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本宝典的支持。如果你想了解更多相关内容请查看下面相关链接
脚本宝典总结
以上是脚本宝典为你收集整理的Hadoop中namenode和secondarynamenode工作机制讲解全部内容,希望文章能够帮你解决Hadoop中namenode和secondarynamenode工作机制讲解所遇到的问题。
本图文内容来源于网友网络收集整理提供,作为学习参考使用,版权属于原作者。
如您有任何意见或建议可联系处理。小编QQ:384754419,请注明来意。
- 使用命令远程注销服务器的方法 2022-04-25
- DELL R720服务器安装Windows Server 2008 R2系统的图文详解 2022-04-25
- TortoiseSvn小乌龟安装最新图文详细教程 2022-04-25
- 网络线路科普之CN2,GIA,CIA,BGP以及IPLC都是什么意思 2022-04-25
- 每天学一分钟使用Git服务器实现查看Debug分支及修复 2022-04-25
- 解决服务器运行jupyter notebook方法 2022-04-25
- 浅析NFS服务器原理以及搭建配置部署步骤 2022-04-25
- 教你如何免费使用aws的服务器资源 2022-04-25
- 详解aws免费服务器申请及网络代理搭建教程 2022-04-25
- 服务器压力测试概念及方法(TPS/并发量) 2022-04-25